Was sind Korotinen in C ++ 20?
Was sind Koroutinen in gekennzeichnete Fragen c ++ 20 ?
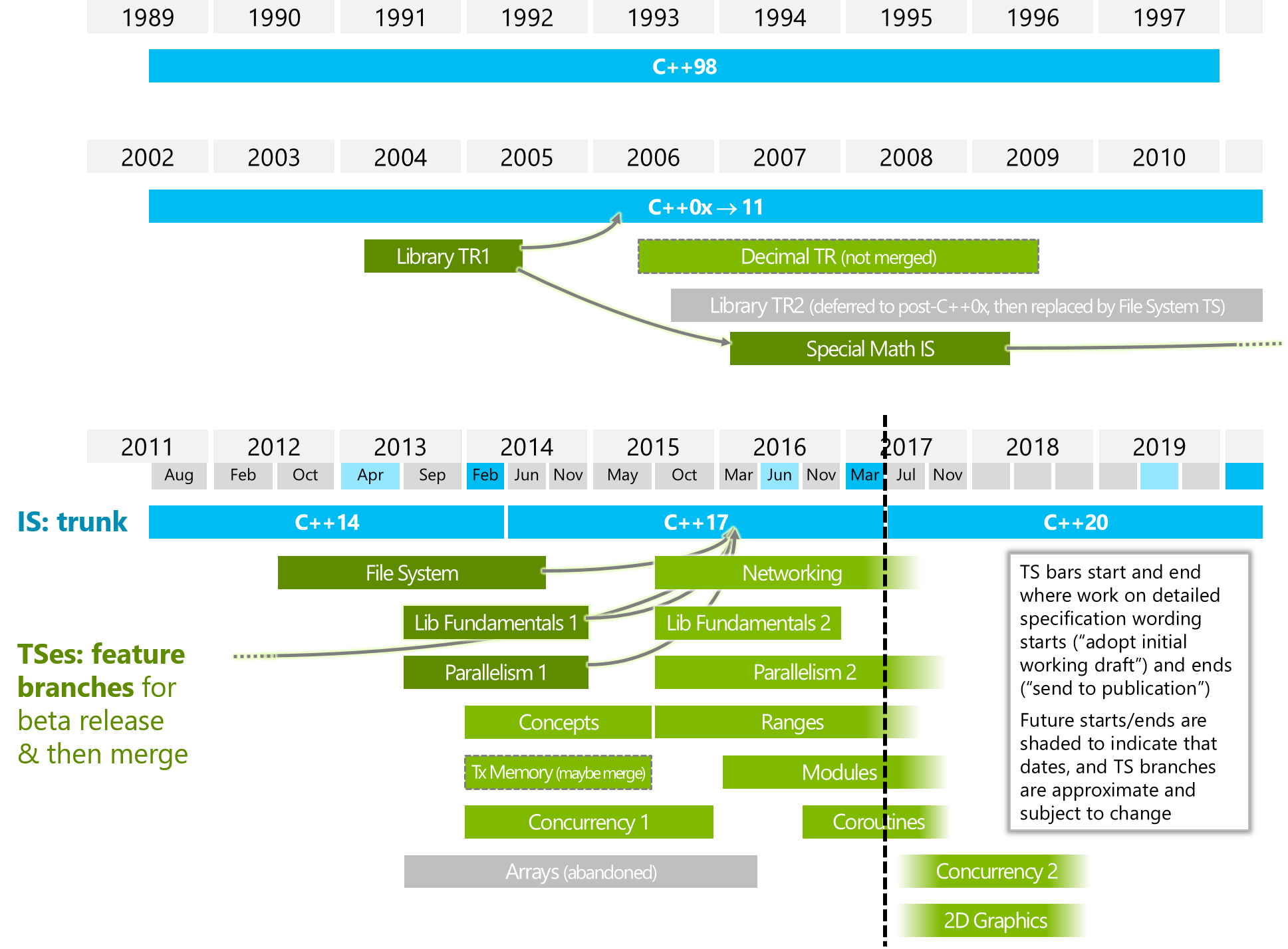
In welcher Hinsicht unterscheidet es sich von "Parallelism2" und / oder "Concurrency2" (siehe Bild unten)?
Das folgende Bild stammt von ISOCPP.
{kind=link}
3 Antworten
Auf einer abstrakten Ebene teilen Coroutinen die Idee, einen Ausführungszustand von der Idee zu haben, einen Thread der Ausführung zu haben.
SIMD (Single Instruction Multiple Data) hat mehrere "Ausführungs-Threads", aber nur einen Ausführungsstatus (es funktioniert nur für mehrere Daten). Argwöhnlich parallele Algorithmen sind ein bisschen so, dass Sie ein "Programm" auf verschiedenen Daten haben.
Threading hat mehrere Ausführungs-Threads und mehrere Ausführungszustände. Sie haben mehr als ein Programm und mehr als einen Ausführungsthread.
Coroutines verfügt über mehrere Ausführungsstatus, besitzt jedoch keinen ausführbaren Thread. Sie haben ein Programm, und das Programm hat Status, aber es hat keinen Thread der Ausführung.
Das einfachste Beispiel für Koroutinen sind Generatoren oder Enumerables aus anderen Sprachen.
Im Pseudocode:
%Vor% Der Generator wird aufgerufen, und beim ersten Aufruf wird 0 zurückgegeben. Ihr Status wird gespeichert (wie viel Status variiert mit der Implementierung von Koroutinen), und das nächste Mal, wenn Sie es aufrufen, setzt es fort, wo es aufgehört hat. So gibt es beim nächsten Mal 1 zurück. Dann 2.
Schließlich erreicht es das Ende der Schleife und fällt vom Ende der Funktion ab; Die Coroutine ist beendet. (Was hier passiert, hängt von der Sprache ab, über die wir sprechen; in Python löst es eine Ausnahme aus).
Coroutinen bringen diese Fähigkeit in C ++.
Es gibt zwei Arten von Koroutinen; stapelbar und stapellos.
Eine stapellose Coroutine speichert nur lokale Variablen in ihrem Zustand und ihrem Ausführungsort.
Eine Stapel-Coroutine speichert einen ganzen Stapel (wie einen Thread).
Stapellose Coroutines können extrem leicht sein. Der letzte Vorschlag, den ich gelesen habe, beinhaltete im Grunde das Umschreiben Ihrer Funktion in etwas wie ein Lambda; Alle lokalen Variablen gehen in den Zustand eines Objekts über, und Beschriftungen werden verwendet, um zu / von dem Ort zu springen, an dem die Coroutine Zwischenergebnisse "produziert".
Der Prozess der Erzeugung eines Wertes wird "Ertrag" genannt, da Koroutinen ein bisschen wie kooperatives Multithreading sind; Sie geben dem Aufrufer den Ausführungspunkt zurück.
Boost hat eine Implementierung von Stapel-Coroutinen; Sie können eine Funktion aufrufen, um für Sie zu produzieren. Stackful Coroutinen sind mächtiger, aber auch teurer.
Es gibt mehr für Coroutinen als einen einfachen Generator. Sie können eine Coroutine in einer Coroutine abwarten, in der Sie Coroutinen sinnvoll zusammenstellen können.
Routinen, wie if, Schleifen und Funktionsaufrufe, sind eine andere Art von "strukturiertem Goto", mit der Sie bestimmte nützliche Muster (wie Zustandsautomaten) auf eine natürlichere Weise ausdrücken können.
Die spezifische Implementierung von Coroutinen in C ++ ist ein bisschen interessant.
Auf seiner grundlegendsten Ebene fügt es C ++ einige Schlüsselwörter hinzu: co_return co_await co_yield , zusammen mit einigen Bibliothekstypen, die damit arbeiten.
Eine Funktion wird zur Koroutine, indem sie eine solche in ihrem Körper hat. Aus ihrer Erklärung sind sie also nicht von Funktionen zu unterscheiden.
Wenn eines dieser drei Schlüsselwörter in einem Funktionskörper verwendet wird, werden einige standardmäßige mandatierte Untersuchungen des Rückgabetyps und der Argumente durchgeführt, und die Funktion wird in eine Coroutine umgewandelt. Diese Überprüfung teilt dem Compiler mit, wo der Funktionszustand gespeichert werden soll, wenn die Funktion angehalten wird.
Die einfachste Coroutine ist ein Generator:
%Vor% co_yield unterbricht die Ausführung der Funktionen, speichert diesen Status in generator<int> und gibt dann den Wert von current durch generator<int> zurück.
Sie können die zurückgegebenen ganzen Zahlen durchlaufen.
co_await lässt Sie zwischenzeitlich eine Coroutine auf eine andere spleißen. Wenn Sie in einer Coroutine sind und Sie die Ergebnisse einer erwarteten Sache (oft eine Coroutine) benötigen, bevor Sie fortfahren, haben Sie co_await darauf. Wenn sie bereit sind, gehen Sie sofort vor; Wenn nicht, warten Sie, bis das Warten auf Sie bereit ist.
load_data ist eine Coroutine, die ein std::future erzeugt, wenn die benannte Ressource geöffnet wird und wir es schaffen, den Punkt zu analysieren, an dem wir die angeforderten Daten gefunden haben.
open_resource und read_line s sind wahrscheinlich asynchrone Coroutinen, die eine Datei öffnen und Zeilen daraus lesen. Der co_await verbindet den Suspending- und den Bereitzustand von load_data mit ihrem Fortschritt.
C ++ - Koroutinen sind viel flexibler als diese, da sie als minimaler Satz von Sprachfunktionen zusätzlich zu Benutzer-Space-Typen implementiert wurden. Die User-Space-Typen definieren effektiv, was co_return co_await und co_yield bedeutet - Ich habe gesehen, wie Leute monadische optionale Ausdrücke so implementieren, dass ein co_await auf einem leeren fakultativen steht automatisch propagiert den leeren Zustand zu den äußeren optional:
statt
%Vor%Eine Coroutine ist wie eine C-Funktion, die mehrere return-Anweisungen enthält und beim zweiten Aufruf nicht zu Beginn der Funktion, sondern erst beim ersten Befehl nach dem letzten ausgeführten request gestartet wird. Dieser Ausführungsort wird zusammen mit allen automatischen Variablen gespeichert, die auf dem Stapel in Nicht-Coroutine-Funktionen leben würden.
Eine frühere experimentelle Coroutinimplementierung von Microsoft verwendete kopierte Stapel, so dass Sie sogar von tief verschachtelten Funktionen zurückkehren konnten. Aber diese Version wurde vom C ++ - Komitee abgelehnt. Sie können diese Implementierung beispielsweise mit der Boosts-Glasfaserbibliothek erhalten.
Koroutinen sollen (in C ++) Funktionen sein, die "warten" können, bis irgendeine andere Routine abgeschlossen ist und alles zur Verfügung stellt, was für die unterbrochene, pausierte, wartende Routine benötigt wird, um weiterzumachen. das Feature, das für C ++ - Leute am interessantesten ist, ist, dass Koroutinen idealerweise keinen Stapelspeicherplatz einnehmen würden ... C # kann schon etwas wie das mit abwarten und ausgeben, aber C ++ muss möglicherweise neu aufgebaut werden, um es zu bekommen.
Nebenläufigkeit konzentriert sich stark auf die Trennung von Anliegen, bei denen ein Anliegen eine Aufgabe ist, die das Programm erfüllen soll. Diese Trennung von Sorgen kann auf eine Reihe von Wegen erreicht werden ... normalerweise in Form von Delegation. Die Idee der Nebenläufigkeit besteht darin, dass eine Reihe von Prozessen unabhängig voneinander ablaufen könnte (Trennung von Belangen), und ein "Zuhörer" würde alles, was von diesen getrennten Belangen produziert wird, dahin lenken, wohin es gehen soll. Dies hängt stark von einer Art asynchroner Verwaltung ab. Es gibt eine Reihe von Ansätzen für Nebenläufigkeit, einschließlich aspektorientierter Programmierung und anderer. C # hat den 'Delegate'-Operator, der ganz gut funktioniert.
Parallelismus klingt wie Nebenläufigkeit und ist möglicherweise beteiligt, ist aber eigentlich ein physikalisches Konstrukt, das viele Prozessoren enthält, die mehr oder weniger parallel mit Software angeordnet sind, die Teile des Codes an verschiedene Prozessoren leiten kann, wo sie ausgeführt werden und die Ergebnisse synchron empfangen werden.