Werte in Pandas DataFrame extrapolieren
2 Antworten
Extrapoliere Pandas DataFrame s
DataFrame s kann vielleicht extrapoliert werden, allerdings gibt es keinen einfachen Methodenaufruf innerhalb von Pandas und benötigt eine andere Bibliothek (zB scipy.optimize ).
Extrapolieren
Extrapolieren erfordert im Allgemeinen, dass bestimmte Annahmen über die Daten extrapoliert werden. Ein Weg ist durch Kurvenanpassung eine allgemeine parametrisierte Gleichung zu den Daten, um Parameterwerte zu finden, die die vorhandenen Daten am besten beschreiben wird dann verwendet, um Werte zu berechnen, die über den Bereich dieser Daten hinausgehen. Das schwierige und einschränkende Problem bei diesem Ansatz besteht darin, dass bei der Auswahl der parametrisierten Gleichung einige Annahmen über den Trend getroffen werden müssen. Dies kann durch Versuch und Irrtum mit verschiedenen Gleichungen gefunden werden, um das gewünschte Ergebnis zu erhalten, oder es kann manchmal aus der Quelle der Daten abgeleitet werden. Die Daten, die in der Frage bereitgestellt werden, sind wirklich nicht groß genug für einen Datensatz, um eine gut angepasste Kurve zu erhalten. es ist jedoch gut genug für die Illustration.
Das folgende Beispiel zeigt die Extrapolation von DataFrame mit einem 3 rd -Ordnungspolynom
f ( x ) = ein x 3 + b x 2 + c x + d (Gl. 1)
Diese generische Funktion ( func() ) passt in jede Spalte, um eindeutige spaltenspezifische Parameter zu erhalten (zB a , b , c , d ). Dann werden diese parametrisierten Gleichungen verwendet, um die Daten in jeder Spalte für alle Indizes mit NaN s zu extrapolieren.
Extrapolierte Ergebnisse
%Vor% Plot für avg Spalte
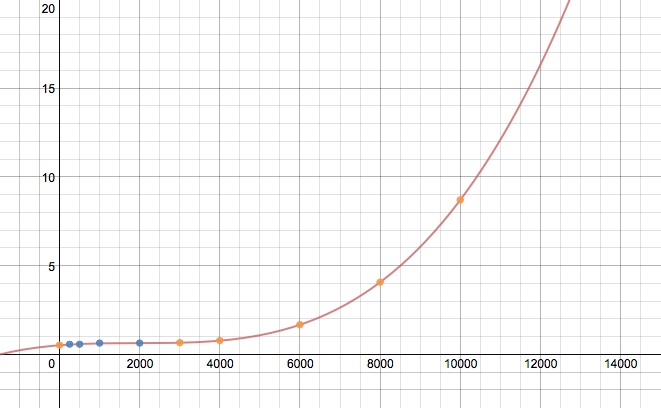
Ohne einen größeren Datensatz oder die Quelle der Daten zu kennen, ist dieses Ergebnis möglicherweise völlig falsch, sollte aber den Prozess zur Extrapolation von DataFrame veranschaulichen. Die angenommene Gleichung in func() müsste wahrscheinlich gespielt werden um die korrekte Extrapolation zu erhalten. Außerdem wurde kein Versuch unternommen, den Code effizient zu machen.
Aktualisierung:
Wenn Ihr Index nicht numerisch ist, wie zum Beispiel ein DatetimeIndex , sehen Sie diese Antwort , um sie zu extrapolieren.
ergibt
%Vor% Hinweis: Ich habe Ihre df etwas geändert, um zu zeigen, dass die Interpolation mit nearest sich von der df.fillna unterscheidet. (Siehe die Zeile mit Index 999.)
Ich fügte auch eine Reihe von NaNs mit Index 0 hinzu, um zu zeigen, dass bfill() auch notwendig sein könnte.
Tags und Links python pandas extrapolation