Ich habe eine Präsentation für Leute, die (fast) keine Ahnung haben, wie eine GPU funktioniert. Ich denke, dass eine GPU tausend Kerne hat, wo eine CPU nur vier bis acht davon hat, ist ein Unsinn. Aber ich möchte meinem Publikum ein Element des Vergleichs geben.
Nachdem ich einige Monate mit NVidias Kepler- und AMDs GCN-Architekturen gearbeitet habe, bin ich versucht, einen GPU-Kern mit einer SIMD-ALU CPU zu vergleichen (I don ' t wissen, ob sie bei Intel einen Namen dafür haben). Ist es fair? Schließlich haben diese Programmiermodelle bei der Betrachtung einer Assembly-Ebene viele Gemeinsamkeiten (zumindest bei GCN, werfen Sie einen Blick auf p2-6 der ISA-Handbuch ).
In diesem Artikel wird erklärt, dass ein Haswell-Prozessor 32 Vorgänge mit einfacher Genauigkeit ausführen kann Zyklus, aber ich nehme an, es gibt Pipelining oder andere Dinge passieren, um diese Rate zu erreichen. Im NVidia-Sprachgebrauch, wie viele Cuda-Kerne hat dieser Prozessor? Ich würde sagen 8 pro CPU-Kern für 32-Bit-Operationen, aber dies ist nur eine Schätzung basierend auf der SIMD Breite.
Natürlich gibt es viele andere Dinge, die beim Vergleich von CPU- und GPU-Hardware zu berücksichtigen sind, aber das ist nicht das, was ich versuche zu tun. Ich muss nur erklären, wie das Ding funktioniert.
PS: Alle Zeiger auf CPU Hardware-Dokumentationen oder CPU / GPU-Präsentationen werden sehr geschätzt!
BEARBEITEN: Danke für deine Antworten, leider musste ich nur einen auswählen. Ich habe Igors Antwort markiert, weil sie am meisten zu meiner anfänglichen Frage passt und mir genügend Informationen gegeben hat, um zu begründen, warum dieser Vergleich nicht funktionieren sollte zu weit gefasst sein, aber CaptainObvious hat sehr gute Artikel zur Verfügung gestellt .
Sehr locker gesagt, ist es nicht völlig unvernünftig zu sagen, dass ein Haswell-Kern ungefähr 16 CUDA-Kerne hat, aber Sie wollen diesen Vergleich definitiv nicht zu weit führen. Sie sollten vorsichtig sein, wenn Sie diese Aussage direkt in einer Präsentation machen, aber ich fand es nützlich, sich einen CUDA-Kern als etwas mit einer skalaren FP-Einheit verwandt zu denken.
Es kann hilfreich sein, wenn ich erkläre, warum Haswell 32 Vorgänge mit einfacher Genauigkeit pro Zyklus ausführen kann.
8 Operationen mit einfacher Genauigkeit werden in jeder AVX / AVX2-Anweisung ausgeführt. Wenn Sie Code schreiben, der auf einer Haswell-CPU ausgeführt wird, können Sie AVX- und AVX2-Anweisungen verwenden, die mit 256-Bit-Vektoren arbeiten. Diese 256-Bit-Vektoren können 8 FP-Nummern mit einfacher Genauigkeit, 8 ganze Zahlen (32 Bit) oder 4 FP-Zahlen mit doppelter Genauigkeit darstellen.
2 AVX / AVX2-Anweisungen können in jedem Kern pro Zyklus ausgeführt werden, obwohl es einige Einschränkungen gibt, in Bezug auf welche Befehle gepaart werden können.
Ein FMA-Befehl (Fuzzy Multiply Add) führt technisch zwei Operationen mit einfacher Genauigkeit aus. FMA-Befehle führen "fusionierte" Operationen wie A = A * B + C aus, so dass es wohl zwei Operationen pro Skalaroperand gibt: eine Multiplikation und eine Addition.
Dieser Artikel erklärt die obigen Punkte im Detail: Ссылка
In der Gesamtbuchhaltung kann ein Haswell-Kern 8 * 2 * 2 Operationen mit einfacher Genauigkeit pro Zyklus ausführen. Da CUDA-Cores auch FMA-Operationen unterstützen, können Sie den Faktor 2 nicht zählen, wenn Sie CUDA-Cores mit Haswell-Cores vergleichen.
Ein Kepler-CUDA-Kern verfügt über eine Gleitkommaeinheit mit einfacher Genauigkeit, sodass er pro Zyklus eine Gleitkommaoperation ausführen kann: Ссылка , Ссылка
Wenn ich Folien daraus zusammenstellen würde, würde ich einen Abschnitt haben, der erklärt, wie viele FP-Operationen Haswell pro Zyklus machen kann: die drei obigen Punkte, plus Sie haben mehrere Kerne und möglicherweise mehrere Prozessoren. Und ich würde einen anderen Abschnitt haben, der erklärt, wie viele FP-Operationen eine Kepler-GPU pro Zyklus ausführen kann: 192 pro SMX, und Sie haben mehrere SMX-Einheiten auf der GPU.
PS .: Ich kann das Offensichtliche sagen, aber um Verwirrung zu vermeiden: Die Haswell-Architektur enthält auch eine integrierte GPU, die eine völlig andere Architektur als die Haswell-CPU hat.
Ich wäre sehr vorsichtig bei dieser Art von Vergleich. Immerhin hat der Begriff "Core", auch in der GPU-Welt, je nach Kontext eine ganz andere Fähigkeit: Der neue AMD GCN unterscheidet sich stark von dem alten VLIW4, der sich von dem CUDA-Core deutlich unterscheidet.
Abgesehen davon, werden Sie Ihrem Publikum mehr Verwirrung als Verständnis bringen, wenn Sie nur einen kleinen Vergleich mit der CPU machen und das war's. Wenn ich du wäre, würde ich noch einen detaillierteren (kann noch schnell sein) Vergleich anstellen. Zum Beispiel jemand, der an CPU gewöhnt ist und wenig Ahnung von GPU hat, könnte sich wundern, warum eine GPU so viele Register haben kann, obwohl sie so teuer ist (in der CPU-Welt). Eine Erklärung zu dieser Frage finden Sie am Ende dieses Beitrags sowie einige Vergleich GPU vs CPU.
Dieser andere Artikel gibt einen guten Vergleich zwischen diesen beiden Arten von Verarbeitungseinheiten, indem er erklärt wie GPUs funktionieren, aber auch wie sie sich entwickelt haben und welche Unterschiede es zu CPUs gibt. Es behandelt Themen wie Datenfluss, Speicherhierarchie, aber auch für welche Art von Anwendungen eine GPU nützlich ist. Nach all der Macht, die eine GPU entwickeln kann, ist (effizient) nur für einige Arten von Problemen zugänglich.
Und persönlich, wenn ich eine Präsentation über GPU machen müsste und die Möglichkeit hätte, nur einen Verweis auf CPU zu machen, wäre es das: die Probleme zu präsentieren, die eine GPU effizient lösen kann, gegenüber denen eine CPU besser umgehen kann .
Als Bonus, obwohl es nicht direkt mit Ihrer Präsentation in Verbindung steht, ist hier ein Artikel , in den sich GPGPU befindet Perspektive, die zeigt, dass einige von einigen Leuten behauptete Beschleunigung überschätzt wird (das hängt mit meinem letzten Punkt zusammen:))
Ich stimme CaptainObvious voll und ganz zu, vor allem, dass die Probleme darstellt, die eine GPU effizient lösen kann gegenüber denen, die eine CPU besser handhaben kann wäre eine gute Idee.
Eine Möglichkeit, CPUs und GPUs zu vergleichen, ist die Anzahl der Operationen / Sek., die sie properieren können. Vergleichen Sie natürlich nicht einen CPU-Kern mit einem Multi-Core-GPU.
Ein SandyBridge-Kern kann 2 AVX-Op / Cycles ausführen, das heißt, 8 Double-Precision-Nummern / Zyklus. Ein Computer mit 16 Sandy-Bridge-Kernen, die mit 2,6 GHz getaktet sind, hat also eine Spitzenleistung von 333 Gflops.
Ein K20-Rechenmodul GK110 hat einen Spitzenwert von 1170 Gflops, also 3,5-mal mehr. Dies ist meiner Meinung nach ein fairer Vergleich, und es sollte betont werden, dass die Spitzenleistung auf der CPU viel einfacher zu erreichen ist (einige Anwendungen erreichen 80% -90% der Spitze) als auf GPU ( besten Fällen) Ich weiß, weniger als 50% der Spitze ).
Um zu summieren, würde ich also nicht auf Architekturdetails eingehen, sondern eher einige Scherzahlen mit der Perspektive angeben, dass der Peak auf GPUs oft weit entfernt ist.
Es ist fairer, GPUs mit vektorisierten CPU-Einheiten zu vergleichen, aber wenn Ihre Zielgruppe keine Vorstellung davon hat, wie GPUs arbeiten, scheint es fair anzunehmen, dass sie ein ähnliches Wissen über vektorisierte SSE-Anweisungen haben.
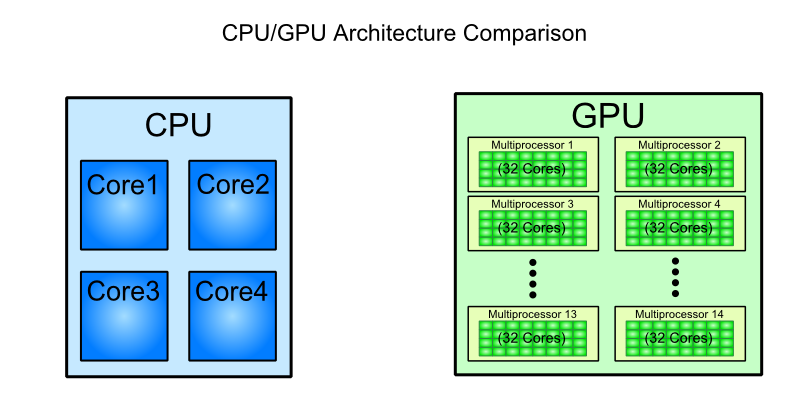
Für Zielgruppen wie diese ist es wichtig, auf die Unterschiede auf hoher Ebene hinzuweisen, z. B. wie sich Blöcke von "Kernen" auf der GPU einen Scheduler teilen und eine Datei registrieren.
Ich würde auf die Übersicht über die GTC-Kepler-Architektur verweisen, um eine bessere Vorstellung davon zu erhalten, wie die Kepler-Architektur aussieht mögen. Dies ist auch ein einigermaßen verständlicher Vergleich zwischen den beiden, wenn Sie sich daran halten wollen die "gpu core" Idee.
{kind=link}