Datenvisualisierung: Blasendiagramme, Venn-Diagramme und Tag-Wolken (oh mein!)
Angenommen, ich habe eine große Liste von Objekten (Tausende oder Zehntausende), von denen jedes mit einer Handvoll Tags versehen ist. Es gibt Dutzende oder Hunderte von möglichen Tags und ihre Verwendung folgt einem typischen Potenzgesetz: Einige Tags werden extrem oft verwendet, aber die meisten sind selten. Alle außer den häufigsten paar Dutzend Tags könnten tatsächlich ignoriert werden.
Nun besteht das Problem darin, die Beziehung zwischen diesen Tags zu visualisieren. Eine Tag Cloud ist eine nette Visualisierung nur ihrer Frequenzen, aber sie ignoriert, welche Tags mit welchen anderen Tags vorkommen. Angenommen, tag: bar tritt nur bei Objekten auf, die ebenfalls markiert sind: foo. Das sollte optisch offensichtlich sein. Ähnlich für drei Tags, die zusammen auftreten.
Sie könnten jedes Tag zu einer Blase machen und sie sich teilweise überlappen lassen.
Technisch gesehen ist das ein Venn-Diagramm, aber es könnte unhandlich sein, es so zu behandeln.
Google-Diagramme können beispielsweise Venn-Diagramme erstellen, jedoch nur für 3 oder weniger Sätze (Tags):
Ссылка
Der Grund, warum sie es auf 3 Sätze beschränken, ist das mehr und es sieht schrecklich aus.
Siehe "Erweiterungen zu höheren Stückzahlen" auf der Wikipedia-Seite: Ссылка
Aber nur, wenn jede mögliche Kreuzung nicht leer ist. Wenn nicht mehr als 3 Tags gleichzeitig auftreten (möglicherweise nach dem Auswerfen der seltenen Tags), könnte eine Sammlung von Venn-Diagrammen funktionieren (wobei die Größe der Bubbles die Tag-Häufigkeit repräsentiert).
Oder vielleicht ein Graph (wie in Scheitelpunkten und Kanten) mit visuell dickeren oder dünneren Kanten, um die Häufigkeit des gemeinsamen Auftretens darzustellen.
Haben Sie Ideen oder Hinweise zu Werkzeugen oder Bibliotheken? Im Idealfall würde ich dies mit Javascript tun, aber ich bin offen für Dinge wie R und Mathematica oder wirklich alles andere. Ich bin glücklich, einige tatsächliche Daten zu teilen (Sie werden lachen, wenn ich Ihnen erzähle, was es darstellt), wenn jemand neugierig ist.
Nachtrag : Die Anwendung, an die ich ursprünglich gedacht hatte, war TagTime , aber mir fällt ein, dass dies auch gut zu Google Maps passt das Problem der Visualisierung der köstlichen Lesezeichen.
4 Antworten
Wenn ich Ihre Frage richtig verstanden habe, ein Bildmatrix sollte schön hier arbeiten. Die Implementierung, an die ich denke, wäre eine n × m-Matrix, in der die markierten Elemente Zeilen sind und jeder Tag-Typ eine separate Spalte ist. Jede Zelle in der Matrix vollständig aus „1“ und „0“, das heißt, ein bestimmtes Element hat entweder einen bestimmten Tag bestehen würde oder nicht.
In der Matrix unten (was ich um 90 Grad gedreht, so dass es in diesem Fenster besser passen würde - so tatsächlich Spalt markierten Elemente repräsentieren, und jede Zeile zeigt das Vorhandensein oder Fehlen eines bestimmten Tages über alle Produkte), i simulierte die Szenario, in dem es 8 Tags und 200 gekennzeichnete Elemente gibt. , eine "0" ist blau und eine "1" ist hellgelb .
Alle Werte in dieser Matrix wurden nach dem Zufallsprinzip ausgewählt (jeder markierte Gegenstand besteht aus acht Ziehungen aus einer Box bestehend aus zwei Spielsteinen, einem blauen und einem gelben (kein Tag und Tag). Es ist also nicht überraschend, dass es keinen visuellen Beweis für ein Muster gibt hier, aber wenn es in Ihren Daten vorhanden ist, diese Technik, die tot ist einfach zu implementieren, können Sie sie finden.
verwendet I R zu erzeugen und die simulierten Daten plotten, nur Basis Grafiken verwendet (keine externen Pakete oder Bibliotheken):
%Vor%alt text http://img690.imageshack.us/img690/3236/imagematrix01.png
Ich würde etwas so erstellen , wenn Sie auf das Web abzielen. Kanten, die die Knoten verbinden, könnten dicker oder dunkler in der Farbe sein, oder vielleicht eine stärkere Kraft, die sie verbindet, so dass sie in der Nähe sind. Ich würde auch den Tag-Namen innerhalb des Kreises hinzufügen.
Einige Bibliotheken, die dafür sehr gut sind, sind:
Einige andere lustige JavaScript-Bibliotheken, die es wert sind, genauer betrachtet zu werden, sind:
Obwohl dies ein alter Faden ist, bin ich heute nur darauf gestoßen.
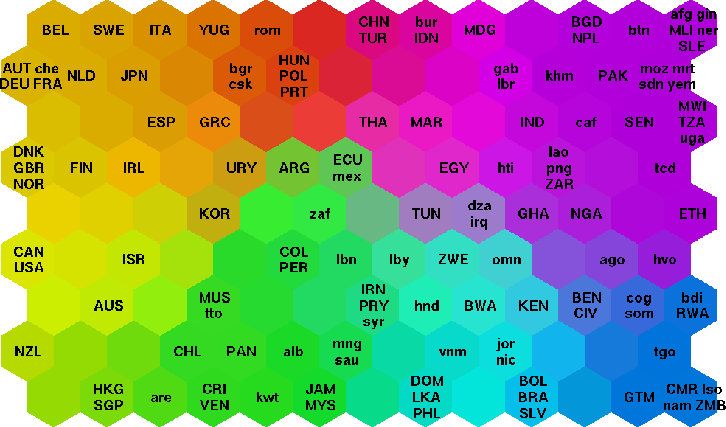
Sie können auch eine selbstorganisierende Karte in Betracht ziehen.
Hier ist ein Beispiel für eine sich selbst organisierende Karte für die Armut in der Welt. Es verwendete 39 von, was Sie Ihre "Umbauten" nennen, um anzuordnen, was Sie Ihre "Gegenstände" nennen.

{kind=link}
{kind=link}
Beachten Sie, dass es funktionieren würde, da ich das nicht getestet habe, aber hier ist, wie ich anfangen würde:
Sie können eine Matrix erstellen, wie es in Ihrer Antwort vorgeschlagen wird, aber statt Dokumente als Zeilen und Tags als Spalten zu verwenden, verwenden Sie eine quadratische Matrix, in der Tags Zeilen und Spalten sind. Wert der Zelle T1; T2 ist die Anzahl der Dokumente, die mit T1 und T2 markiert sind (beachten Sie, dass Sie dadurch eine symmetrische Matrix erhalten, weil [T1; T2] den gleichen Wert wie [T2; T1] hat) .
Sobald Sie dies getan haben, ist jede Zeile (oder Spalte) ein Vektor, der das Tag in einem Raum mit T-Dimensionen lokalisiert. Tags nahe beieinander in diesem Raum treten oft zusammen auf. Um das Co-Vorkommen zu visualisieren, können Sie dann eine Methode verwenden, um Ihre Raumdimensionalität oder eine beliebige Clustermethode zu reduzieren. Sie können zum Beispiel eine selbstorganisierende Karte von kohonen verwenden, um Ihren T-Dimensionen-Raum in einen 2D-Raum zu projizieren. Sie erhalten dann eine 2D-Matrix, in der jede Zelle einen abstrakten Vektor im Tag-Raum darstellt (dh der Vektor ist nicht notwendig) in Ihrem Datensatz). Dieser Vektor spiegelt eine topologische Einschränkung des Quellraums wider und kann als "Modellvektor" betrachtet werden, der ein signifikantes Zusammentreffen einiger Tags widerspiegelt. Darüber hinaus werden Zellen, die sich auf dieser Karte nahe beieinander befinden, Vektoren darstellen, die im Quellbereich nahe beieinander liegen. Auf diese Weise können Sie den Tag-Raum auf einer 2D-Matrix abbilden
Die endgültige Visualisierung der Matrix kann auf viele Arten erfolgen, aber ich kann Ihnen dazu keinen Rat geben, ohne vorher die Ergebnisse der vorherigen Verarbeitung zu sehen.
Tags und Links javascript r charts visualization data-visualization