Ich möchte Daten persistent für meine Anwendung speichern, aber ich brauche keine vollständige relationale Datenbank. Ich könnte wirklich mit einem grundlegenden "Cache" -artigen persistenten Speicher auskommen, wo die Struktur nur ein (Schlüssel, Wert) Paar ist.
Anstelle einer Datenbank, was sind meine besten, skalierbaren Optionen?
Es gibt immer SQLite , eine Datenbank, die in einer Datei gespeichert ist. SQLite hat bereits eine integrierte Nebenläufigkeit, so dass Sie sich nicht um Dinge wie Dateisperren kümmern müssen, und es ist wirklich schnell für Lesevorgänge.
Wenn Sie jedoch viele Datenbankänderungen vornehmen, sollten Sie sie alle gleichzeitig in einer Transaktion ausführen . Dadurch werden die Änderungen nur einmal in die Datei geschrieben, und nicht bei jeder Ausgabe einer Änderungsabfrage. Dies erhöht die Geschwindigkeit der Durchführung mehrerer Änderungen dramatisch.
Wenn eine Änderungsanfrage ausgegeben wird, unabhängig davon, ob sie sich in einer Transaktion befindet oder nicht, wird die gesamte Datenbank gesperrt, bis diese Abfrage beendet ist. Dies bedeutet, dass extrem große Transaktionen die Leistung anderer Prozesse beeinträchtigen können, da sie auf den Abschluss der Transaktion warten müssen, bevor sie auf die Datenbank zugreifen können. In der Praxis habe ich nicht festgestellt, dass dies so auffällig ist, aber es ist immer eine gute Übung, zu versuchen, die Anzahl der von Ihnen ausgeführten Datenbankmodifizierungsabfragen zu minimieren.
Wenn Sie einen 'persistenten Cache' haben möchten und bereits memcached verwenden, überprüfen Sie memcachedb . Es ist eine persistente Hashtable mit dem Memcached-Protokoll, keine Notwendigkeit für einen neuen Client (aber einen neuen Daemon)
Ich frage kürzlich eine ähnliche Frage . Hier sind einige Möglichkeiten:
Wenn Sie Skalierbarkeit benötigen, ist ein RDBMS die beste Wahl. Auf der grundlegendsten Ebene können Sie Datenstrukturen in Dateien serialisieren - allerdings müssten Sie dann Probleme mit der Dateisperrung berücksichtigen, die den gleichzeitigen Zugriff einschränken würden.
SQLite ist eine SQL-Datei-basierte Datenbank-Engine, die ohne persistenten Datenbank-Daemon (in PHP zum Beispiel läuft es als eine Erweiterung) ausgeführt werden kann, aber es hat auch Nebenläufigkeit Probleme (lesen Sie die Antworten zu diese Frage , die Ihnen helfen könnte zu entscheiden, ob SQLite das Richtige für Sie ist).
Wenn Sie nicht wirklich einen guten Grund haben, kein echtes DRBMS zu verwenden, würde ich vorschlagen, dass Sie bei MySQL oder anderen "vollwertigen" Engines bleiben.
Wenn Sie etwas wirklich Skalierbares wollen, würde ich mich nicht für eine flache oder XML-Datei entscheiden. Wenn Ihre Daten wachsen, könnte Ihre Leistung beeinträchtigt werden.
Wenn Sie irgendwann eine Menge Daten haben , würde ich mich trotzdem für eine Datenbank entscheiden - ich würde mir etwas wie SQLIte mit einem sehr einfachen Schema, das Ihren Anforderungen entspricht.
Wenn Sie Java schreiben, dann gibt es Java-Datenbank-Implementierungen (Jared erwähnt hsqldb, es gibt andere), die Sie direkt einbeziehen können.
SQLite eignet sich für die statische Einfügung, Sie können jedoch auch MySQL in Ihre Anwendung einschließen, wenn Sie eine kompatible Sprache wie C verwenden.
Ich denke, dass Sie es begrüßen würden, auch SQL zur Verfügung zu haben. XML-Dateien schneiden es einfach nicht mehr ab, vielleicht vor ein paar Jahren beim Schreiben von PDA-Software, aber auch das iPhone und Android enthalten nun SQLite.
Für Schlüssel = Wert-Paare können Sie das INI-Dateiformat mit einfachen Lade- und Speicherprozeduren verwenden, um es zu laden und in der Hash-In-Memory-Tabelle zu speichern.
Das kann später zu irgendwas hochskalieren, nur durch Ändern der Lade- und Speicherprozeduren, um mit db zu arbeiten.
Sie können CounchDB ausprobieren, es ist eine sehr flexible dokumentenorientierte Datenbank, die Sie nicht zur Definition eines Schemas zwingt im Voraus. Es wurde in Erlang geschrieben und ist daher eine sehr skalierbare Lösung. Es kann leicht über eine REST-Schnittstelle abgefragt werden.
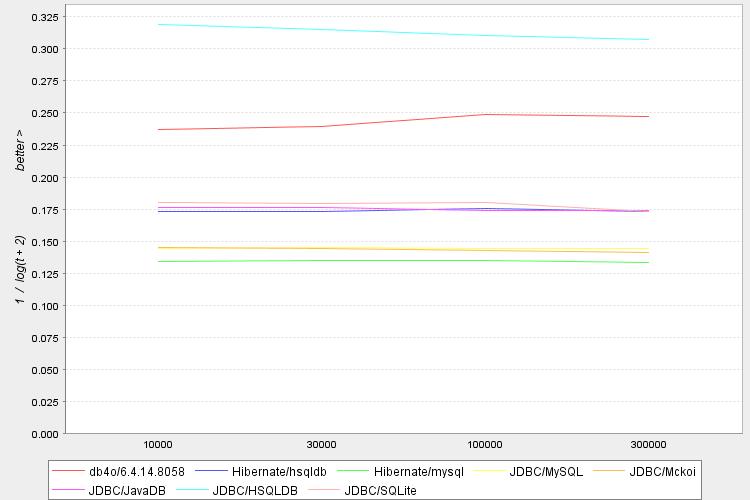
hsqldb im In-Memory-Modus wird Ihnen eine viel bessere Leistung als Flat-File-basierte Datenbanken geben. Es ist ziemlich einfach zu benutzen. Und wenn die Tabelle zu groß wird, gibt es eine Option, sie auch auf der Festplatte zwischenzuspeichern. Sehen Sie sich diesen Leistungsvergleich an:
Tags und Links database caching memcached scalability
{kind=link}