Sql: Optimierung der BETWEEN-Klausel
Ich habe eine Aussage geschrieben, die fast eine Stunde dauert, also frage ich Hilfe, damit ich das schneller machen kann. So, hier gehen wir:
Ich mache eine innere Verbindung von zwei Tabellen:
Ich habe viele Zeitintervalle, die durch Intervalle repräsentiert werden, und ich möchte Messdaten von Messungen nur innerhalb dieser Intervalle erhalten.
intervals : hat zwei Spalten, eine ist die Startzeit, die andere die Endzeit des Intervalls (Anzahl der Zeilen = 1295)
measures : hat zwei Spalten, eine mit der Kennzahl, die andere mit der Zeit, zu der die Kennzahl erstellt wurde (Anzahl der Zeilen = eine Million)
Das Ergebnis, das ich erhalten möchte, ist eine Tabelle, in der in der ersten Spalte die Messung, dann die Zeit der Messung, die Anfangs- / Endzeit des betrachteten Intervalls (es würde für eine Zeile mit einer Zeit innerhalb der Zeit wiederholt werden betrachtete Reichweite)
Hier ist mein Code:
%Vor%Danke
9 Antworten
Das ist ein ziemlich häufiges Problem.
Plain B-Tree Indizes sind nicht gut für die Abfragen wie folgt:
Ein Index ist gut zum Suchen der Werte innerhalb der gegebenen Grenzen, wie folgt:
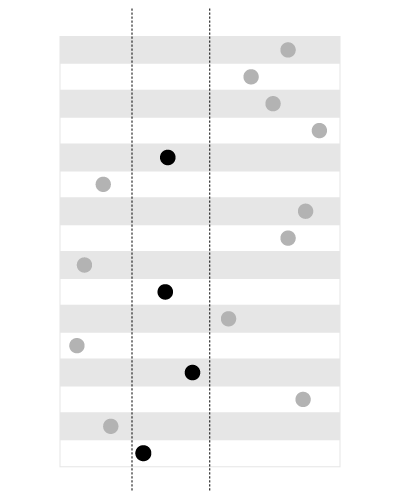
, aber nicht zum Suchen der Grenzen, die den gegebenen Wert enthalten, wie folgt:
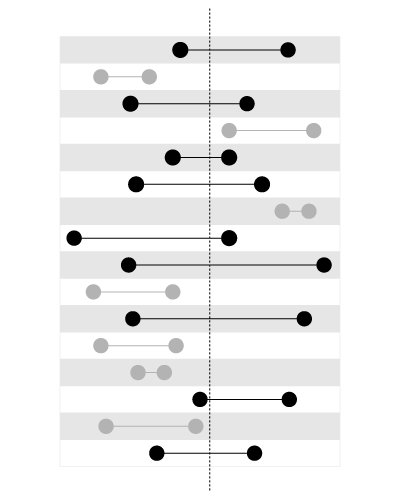
Dieser Artikel in meinem Blog erklärt das Problem genauer:
(das geschachtelte Mengenmodell behandelt den ähnlichen Prädikatstyp).
Sie können den Index auf time setzen, auf diese Weise wird der intervals im Join führen, die entfernte Zeit wird innerhalb der verschachtelten Schleifen verwendet. Dies erfordert eine Sortierung in time .
Sie können einen räumlichen Index für intervals (verfügbar in MySQL mit MyISAM storage) erstellen, der start und end in einer Geometriespalte enthält. Auf diese Weise kann measures im Join führen und es wird keine Sortierung benötigt.
Die räumlichen Indizes sind jedoch langsamer, daher ist dies nur dann effizient, wenn Sie wenige Takte, aber viele Intervalle haben.
Da Sie nur wenige Intervalle, aber viele Kennzahlen haben, stellen Sie sicher, dass Sie einen Index für measures.time :
Aktualisierung:
Hier ist ein Beispielskript zum Testen:
%Vor%Diese Abfrage:
%Vor% verwendet NESTED LOOPS und gibt in 1.7 Sekunden zurück.
Diese Abfrage:
%Vor% verwendet MERGE JOIN und ich musste es nach 5 Minuten stoppen.
Update 2:
Sie werden wahrscheinlich die Engine zwingen müssen, die richtige Tabellenreihenfolge in der Verknüpfung zu verwenden, indem Sie einen Hinweis wie diesen verwenden:
%Vor% Der Optimierer von Oracle ist nicht intelligent genug, um zu sehen, dass sich die Intervalle nicht schneiden. Deshalb wird measures höchstwahrscheinlich als führende Tabelle verwendet (was eine weise Entscheidung wäre, sollten sich die Intervalle überschneiden).
Update 3:
%Vor% Diese Abfrage teilt die Zeitachse in die Bereiche auf und verwendet eine HASH JOIN , um die Kennzahlen und Zeitstempel der Bereichswerte zu verbinden, wobei später eine Feinfilterung durchgeführt wird.
Siehe diesen Artikel in meinem Blog für detailliertere Erklärungen, wie es funktioniert:
Zusammenfassend: Ihre Abfrage wird mit dem gesamten Satz von MEASURES ausgeführt. Es passt die Zeit jedes MEASURES-Datensatzes an einen INTERVALS-Datensatz an. Wenn das Fenster der Zeiten, die von INTERVALS überspannt werden, ungefähr dem Fenster ähnelt, das von MEASURES überspannt wird, wird Ihre Abfrage außerdem gegen den vollständigen Satz INTERVALS ausgeführt, andernfalls wird es gegen eine Teilmenge ausgeführt.
Warum das so ist, liegt daran, dass dadurch der Umfang der Optimierung verringert wird, da ein vollständiger Tabellenscan wahrscheinlich der schnellste Weg ist, um alle Zeilen zu erhalten. Also, es sei denn, Ihre realen MESSWERTE oder INTERVALS Tabellen haben viel mehr Spalten als Sie uns geben, ist es unwahrscheinlich, dass irgendwelche Indizes viel Vorteil geben.
Die möglichen Strategien sind:
- überhaupt keine Indizes
- Index zu MASSNAHMEN (ZEIT, MASS)
- Index zu MASSNAHMEN (ZEIT)
- kein Index für MASSNAHMEN
- Index auf INTERVALS (ENTRY_TIME, EXIT_TIME)
- Index auf INTERVALS (ENTRY_TIME)
- kein Index zu INTERVALS
- parallele Abfrage
Ich werde keine Testfälle für alle Permutationen präsentieren, weil die Ergebnisse so sind, wie wir es erwarten würden.
Hier sind die Testdaten. Wie Sie sehen können, verwende ich etwas größere Datensätze. Das INTERVALS-Fenster ist größer als die MEASURES-Fenster, aber nicht viel. Die Intervalle sind 10000 Sekunden breit und die Messungen werden alle 15 Sekunden durchgeführt.
%Vor%NB In meinen Testdaten habe ich angenommen, dass INTERVAL-Datensätze sich nicht überschneiden. Dies hat eine wichtige Gemeinsamkeit: Ein MEASURES-Datensatz verbindet sich nur mit einem INTERVAL.
Benchmark
Hier ist der Benchmark ohne Indizes.
%Vor%MASSNAHMEN-Tests
Erstellen wir nun einen eindeutigen Index für INTERVALS (ENTRY_TIME, EXIT_TIME) und probieren Sie die verschiedenen Indexierungsstrategien für MEASURES aus. Zuerst, nur eine Index MESSEN TIME Spalte.
%Vor%Lassen Sie uns jetzt die Spalten MEASURES.TIME und MEASURE indexieren
%Vor%Jetzt ohne Index für MASSNAHMEN (aber immer noch ein Index für INTERVALS)
%Vor%Was für einen Unterschied macht die parallele Abfrage?
%Vor%MASSNAHMEN Schlussfolgerung
Nicht viel Unterschied in der verstrichenen Zeit für die verschiedenen Indizes. Ich war etwas überrascht, dass das Erstellen eines Indexes für MEASURES (TS, MEASURE) zu einem vollständigen Tabellenscan und einer etwas langsameren Ausführungszeit führte. Auf der anderen Seite ist es nicht verwunderlich, dass die parallele Abfrage viel schneller ist. Wenn Sie also Enterprise Edition haben und die CPUs zur Verfügung haben, reduziert die Verwendung von PQ definitiv die verstrichene Zeit, obwohl es die Ressourcenkosten nicht viel ändert (und tatsächlich eine Menge mehr sortiert).
INTERVALS Tests
Was für einen Unterschied könnten die verschiedenen Indizes von INTERVALS machen? In den folgenden Tests behalten wir einen Index für MASSNAHMEN (TS) bei. Zuerst werden wir den Primärschlüssel in beiden INTERVALS-Spalten löschen und ihn nur durch eine Einschränkung auf INTERVALS (ENTRY_TIME) ersetzen.
%Vor%Zuletzt ohne Index für INTERVALS überhaupt
%Vor%INTERVALS-Schlussfolgerung
Der Index auf INTERVALS macht einen kleinen Unterschied. Das heißt, die Indizierung (ENTRY_TIME, EXIT_TIME) führt zu einer schnelleren Ausführung. Dies liegt daran, dass es einen schnellen vollständigen Indexscan statt eines vollständigen Tabellenscan erlaubt. Dies wäre bedeutender, wenn das von INTERVALS abgegrenzte Zeitfenster wesentlich größer wäre als das von MASSNAHMEN.
Allgemeine Schlussfolgerungen
Da wir vollständige Tabellenabfragen durchführen, hat keiner der Indizes die Ausführungszeit wesentlich geändert. Wenn Sie also Enterprise Edition und mehrere CPUs haben, erhalten Sie mit Parallel Query die besten Ergebnisse. Andernfalls wären die besten Indizes INTERVALS (ENTRY_TIME, EXIT_TIME) und MEASURES (TS). Die Nested Loops-Lösung ist definitiv schneller als die Parallel Query - siehe Edit 4 .
Wenn Sie gegen eine Untergruppe von MASSNAHMEN (sagen wir eine Woche) vorgingen, würde das Vorhandensein von Indizes größere Auswirkungen haben. Es ist wahrscheinlich, dass die beiden, die ich im vorherigen Absatz empfohlen habe, am effektivsten bleiben würden.
>Letzte Beobachtung: Ich habe dies auf einem Standard-Dual-Core-Laptop mit einem SGA von nur 512M ausgeführt. Trotzdem haben alle meine Fragen weniger als sechs Minuten gedauert. Wenn Ihre Abfrage wirklich eine Stunde dauert, hat Ihre Datenbank einige schwerwiegende Probleme. Obwohl diese lange Laufzeit ein Artefakt von überlappenden INTERVALS sein könnte, was zu einem kartesischen Produkt führen könnte.
** Bearbeiten **
Ursprünglich habe ich die Ausgabe von
aufgenommen %Vor%Aber leider SO streng hat meinen Beitrag gekürzt. Also habe ich es umgeschrieben, aber ohne Ausführung oder Statistik. Diejenigen, die meine Ergebnisse validieren möchten, müssen die Abfragen selbst ausführen.
Bearbeiten 4 (vorherige Bearbeitung wurde aus Platzgründen entfernt)
Beim dritten Versuch konnte ich die Leistungsverbesserung für Quassnois Lösung reproduzieren.
%Vor%So Nested Loops sind definitiv der Weg zu gehen.
Nützliche Lektionen aus der Übung
- Laufende Diagnosetests sind viel mehr wertvoll als Raten und Theoretisieren
- Das Verständnis der Daten ist entscheidend
- Selbst mit 11g sind wir immer noch so müssen Hinweise verwenden, um die Optimierer in bestimmten Fällen
Das erste, was ich mache, ist, dass Ihr Datenbank-Tool einen Ausführungsplan erzeugt, den Sie einsehen können (das ist "Control-L" in MSSQL, aber ich weiß nicht, wie ich das in Oracle machen soll) - das wird versuchen weisen Sie auf die langsamen Teile hin und, abhängig von Ihrem Server / Editor, kann es sogar einige grundlegende Indizes empfehlen. Sobald Sie einen Ausführungsplan haben, können Sie nach Tabellen-Scans für innere Schleifen-Joins suchen, die beide sehr langsam sind - Indizes können bei Tabellen-Scans helfen, und Sie können zusätzliche Join-Prädikate hinzufügen, um Loop-Joins zu verringern.
Meine Vermutung wäre, dass die MEASURES einen Index für die Spalte TIME benötigt und Sie können auch die Spalte MEASURE in die Suche nach Geschwindigkeit aufnehmen. Versuchen Sie Folgendes:
%Vor%Auch wenn dies Ihren Ausführungsplan nicht ändert oder Ihre Abfrage nicht beschleunigt, kann es Ihre Join-Klausel ein wenig leichter lesen lassen:
%Vor%Dies kombiniert Ihre beiden & lt; = und & gt; = in einer einzigen Anweisung.
Ihr SQL entspricht:
%Vor%Das einzige, was ich vorschlagen könnte, ist sicherzustellen, dass es einen Index für m.Time gibt. Wenn dies die Leistung nicht verbessert, versuchen Sie, Indizes für i.Start_Time und i.End_Time hinzuzufügen.
Es gibt möglicherweise eine sehr effiziente Möglichkeit, diese Abfrage zu schreiben, wenn die Intervalle deterministisch sind, weil die Abfrage in einen Equi-Join umgewandelt werden könnte, der effizienterem Hash-Joining zugänglich wäre.
Zum Beispiel, wenn die Intervalle alle stündlich sind:
%Vor%Dann kann der Join wie folgt geschrieben werden:
%Vor%Dies würde die Kosten für alles bis einschließlich des Joins auf einen vollständigen Scan der einzelnen Tabellen reduzieren.
Da Sie jedoch die ORDER BY-Operation dort haben, glaube ich, dass eine Sortierungszusammenführung sie noch immer schlagen kann, da die Abfrage gerade geschrieben wird, weil der Optimierer einen kleineren Datensatz für die Sortierzusammenführung sortiert als er es tun würde für den Hash-Join (weil in letzterem Fall mehr Spalten von Daten sortiert werden müssten). Sie könnten dies umgehen, indem Sie die Abfrage wie folgt strukturieren:
%Vor%Dies ergibt einen niedrigeren Kostenvoranschlag als eine Sortier-Zusammenführung auf meiner 10.2.0.4 Testinstanz, aber ich würde es als etwas riskant betrachten.
Also würde ich nach einer Art Zusammenführung suchen oder sie neu schreiben, um die Verwendung eines Hash-Joins zu ermöglichen, wenn möglich.
Da ich nicht weiß, welches Datenbanksystem und welche Version ich verwende, würde ich sagen, dass (fehlende) Indexierung und die Join-Klausel das Problem verursachen könnten.
Für jeden Datensatz in der Measingtabelle können Sie mehrere Datensätze in der Intervalltabelle ( intervals.entry_time<=measures.time ) haben, und für jeden Datensatz in der Intervalltabelle können Sie mehrere Datensätze in measure ( measures.time <=intervals.exit_time ) haben. Die resultierenden Eins-zu-viele- und Viele-zu-eins-Beziehungen, die durch den Join verursacht werden, bedeuten mehrere Tabellenscans für jeden Datensatz. Ich bezweifle, dass das kartesische Produkt der richtige Begriff ist, aber es ist ziemlich nah.
Das Indizieren würde definitiv helfen, aber es würde noch mehr helfen, wenn Sie einen besseren Schlüssel finden könnten, um die beiden Tabellen zu verbinden. Wenn die Eins-zu-viele-Beziehungen nur in eine Richtung gehen, würde dies definitiv die Verarbeitung beschleunigen, da nicht jede Tabelle / jeder Index zweimal für jeden Datensatz abgetastet werden müsste.
Sie werden die meisten Zeilen aus beiden Tabellen in diesem Fall bekommen, und Sie haben eine Sortierung.
Die Frage ist, braucht der aufrufende Prozess wirklich alle Zeilen oder nur die ersten? Dies würde ändern, wie ich die Abfrage optimieren würde.
Ich nehme an, dass Ihr Aufrufprozess ALLE Zeilen benötigt. Da das Join-Prädikat nicht auf einer Gleichheit basiert, würde ich sagen, dass ein MERGE JOIN der beste Ansatz sein kann. Ein Merge-Join erfordert, dass seine Datenquellen sortiert werden. Wenn wir also eine Sortierung vermeiden können, sollte die Abfrage so schnell wie möglich ausgeführt werden (wobei interessantere Ansätze wie spezialisierte Indizes oder materialisierte Views ausgeschlossen werden).
Um die SORT-Operationen für intervals und measures zu vermeiden, könnten Sie Indizes für ( measures.time , measures.measure ) und ( intervals.entry_time , intervals.exit_time ) hinzufügen. Die Datenbank kann den Index verwenden, um eine Sortierung zu vermeiden, und sie wird schneller sein, da sie keine Tabellenblöcke aufrufen muss.
Wenn Sie nur einen Index für measures.time haben, kann die Abfrage auch ohne Hinzufügen eines weiteren großen Indexes fehlerfrei ausgeführt werden - sie wird jedoch langsamer ausgeführt, da wahrscheinlich viele Tabellenblöcke gelesen werden müssen, um die% co_de zu erhalten % für die SELECT-Klausel.