Ich habe einen HDP 2.4 Cluster mit den folgenden Diensten / Komponenten:
Ich habe seit einigen Tagen nach diesem gesucht und würde einige Hilfe schätzen. Ich habe die folgenden zwei Fragen:
Vielen Dank für Ihre Hilfe!
Wenn Sie eine Anwendung schreiben, die einen oder mehrere HDP-Dienste nutzt, würde ich empfehlen, die Datei log4j.properties für jeden dieser Dienste so zu aktualisieren, dass sie der von Ihnen gewünschten Protokollierungsstufe entspricht. Der beste Weg dazu ist die Verwendung der Ambari-Admin-Benutzeroberfläche. Führen Sie die folgenden Schritte aus, um die log4j.properties eines Dienstes zu bearbeiten:
- Klicken Sie auf einen der Dienste auf der linken Seite des Dashboards.
- Sobald die Seite "Service Summary" geladen wurde, klicken Sie oben auf dem Bildschirm auf die Registerkarte "Configs".
- Klicken Sie unter der Timeline des Versionsverlaufs auf die Registerkarte "Erweitert", suchen Sie nach den Eigenschaften "Erweitert" und suchen Sie nach dem Eintrag log4j.properties. Ist dies nicht der Fall, können Sie in der Suchleiste oben rechts auf dem Bildschirm nach 'log4j' suchen, und Ambari hebt die relevanten Einstellungen hervor.
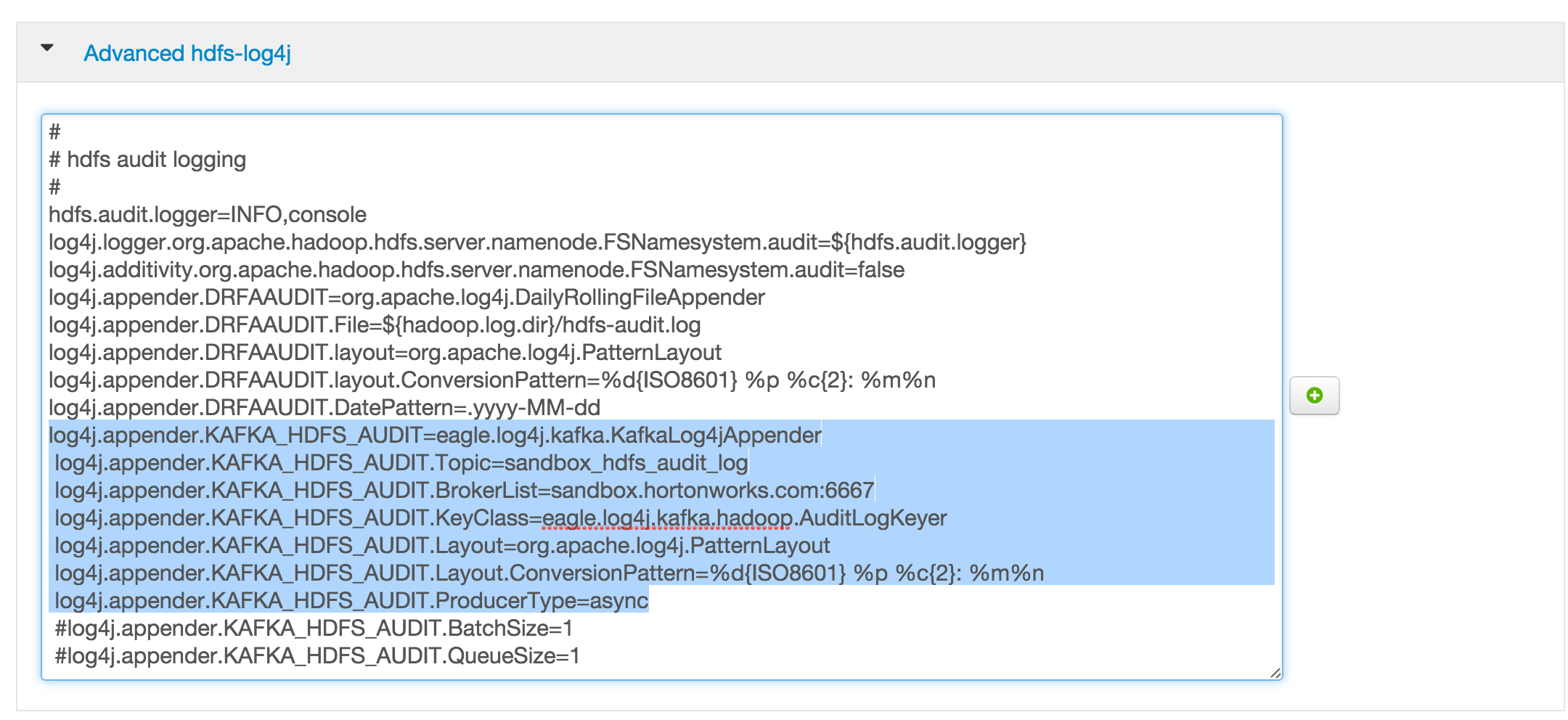
Siehe hier für ein Bild, das ein Beispiel für die Datei log4j.properties zeigt der HDFS-Dienst.
Beachten Sie, dass die Protokolldateien für jeden dieser Dienste nur die Interaktion zwischen Ihrer Anwendung und diesem Dienst erfassen nur . Wenn Sie in Java arbeiten, würde ich Ihnen persönlich empfehlen, eine log4j-Instanz in Ihre Anwendung aufzunehmen. Wenn Sie nicht wissen, wie dies zu tun ist, ist meine Empfehlung zu folgen dieses Tutorial (gefunden auf diese SO-Frage ) zu bekommen Sie richten sich korrekt ein. Je nachdem, wie Ihre Anwendung die APIs der einzelnen Dienste aufruft, können Sie die Ausgabe des Befehls abfragen und in Ihrer eigenen Protokolldatei protokollieren.
Für die Anzeige von Protokolldateien an einem zentralen Ort haben Sie zwei Optionen:
Ich werde die beiden folgenden Optionen skizzieren.
Ich würde riskieren, dass die "einfachere" Methode (damit meine ich die geringste Anstrengung von Ihrer Seite) wäre, Ihren Cluster auf HDP 2.5 zu aktualisieren. Die aktualisierte Hortonworks Data Platform bringt Ambari mit der neuesten Version Ambari 2.4 eine umfassende Überarbeitung. Diese Version enthält Ambari Infra, mit der Sie alle Protokolldateien anzeigen, nach Protokollierungsstufen filtern und Grafiken und komplexe Funktionen ausführen können, dank Ambari-Protokollsuche .
Wenn es nicht möglich ist, den gesamten Cluster zu aktualisieren, besteht eine andere Möglichkeit darin, das Ambari 2.4-Repository von der Hortonworks-Website zu beziehen und es manuell zu installieren. Ein Vertreter von Hortonworks hat mir geraten, dass Ambari 2.4 ohne Probleme auf HDP 2.4 laufen kann, also könnte dies eine machbare Alternative sein ... Obwohl ich empfehlen würde, dass Sie sich vor dem Versuch mit Hortonworks selbst in Verbindung setzen sollten!
Der einzige Nachteil von Ambari Log Search besteht darin, dass Sie Ihre Anwendungsprotokolle nicht in die Suche einbeziehen können - Ambari Log Search ist nur für Hadoop-Dienste verfügbar.
Wenn Sie nicht auf Ambari 2.4 upgraden möchten, dann scheinen andere Optionen etwas knapp zu sein. Ich kenne keine Open-Source-Lösungen persönlich und einige oberflächliche Googeln bringt nur wenige Ergebnisse. Apache Chukwa und Cloudera Schreiber sollen beide die verteilte Log-Sammlung in Hadoop ansprechen, sind aber beide 9 Jahre alt. Es gibt auch einen älteren Hortonworks-Prozess für die Log-Sammlung, der Flume nutzt für den gleichen Prozess, der einen Blick wert ist. Diese SO thread empfiehlt Flume auch für andere Situationen. Es könnte sich lohnen, einige Logs aus jedem Server /var/log/ -Verzeichnis mit Flume zu sammeln.
Der Vorteil dieser Lösung besteht darin, dass Ihre Anwendungsprotokolldateien als Quelle in den Flume-Arbeitsablauf aufgenommen und in die anderen HDP-Dienstprotokolle aufgenommen werden können (je nachdem, wo Sie sie bereitstellen).
Wenn Sie HDP verwenden, sollten Sie diesen Artikel überprüfen (zeigt, wie man log4j konfiguriert):
Wie zu kontrollieren Größe der Protokolldateien für verschiedene HDP-Komponenten?
Dies ist auch sehr nützlich (zeigt, wie man HDFS-Logs mit log4j zippen kann):
Wie man rotiert sowie zip die NameNode-Protokolle mit log4j Extras Feature?
Tags und Links java hadoop log4j hbase hortonworks-data-platform
{kind=link}