Ich bin ein Neuling für Apache Spark.
Mein Job besteht darin, zwei CSV-Dateien zu lesen, bestimmte Spalten daraus auszuwählen, sie zusammenzuführen, zu aggregieren und das Ergebnis in eine einzige CSV-Datei zu schreiben.
Zum Beispiel
Ich lade beide CSV in Datenrahmen.
Und dann in der Lage, den dritten Datenrahmen mit mehreren Methoden join,select,filter,drop im Datenrahmen
Ich kann das auch mit mehreren RDD.map()
Und ich kann das auch tun, indem ich hiveql mit HiveContext
Ich möchte wissen, welches der effiziente Weg ist, wenn meine CSV-Dateien riesig sind und warum?
Sowohl DataFrames als auch Spark-SQL-Abfragen werden mithilfe der Catalyst-Engine optimiert. Daher würde ich annehmen, dass sie eine ähnliche Leistung erbringen werden (vorausgesetzt, Sie verwenden Version & gt; = 1.3)
Und beide sollten besser als einfache RDD-Operationen sein, denn für RDDs hat spark keinerlei Kenntnisse über die Datentypen, so dass es keine speziellen Optimierungen machen kann
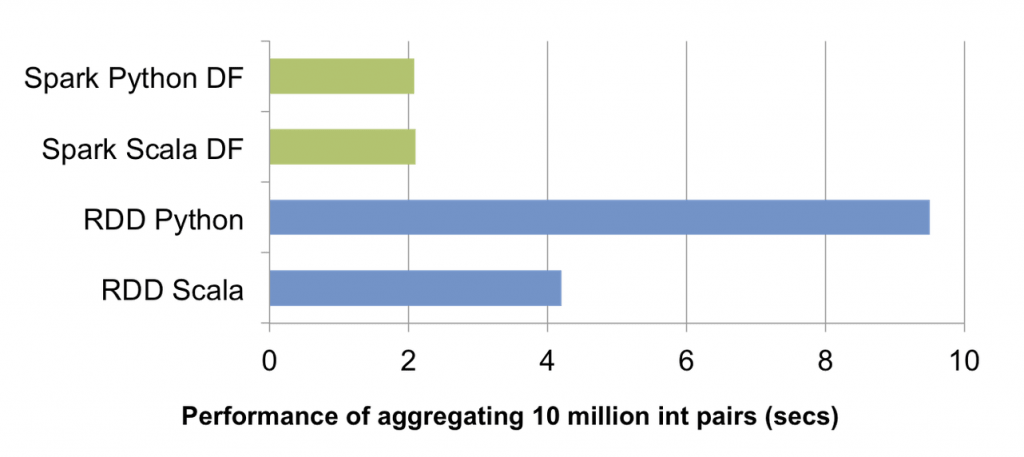
Dieser Blog enthält die Benchmarks. Dataframes ist viel effizienter als RDD
Hier ist der Ausschnitt aus dem Blog
Auf einer hohen Ebene gibt es zwei Arten von Optimierungen. Zuerst wendet Catalyst logische Optimierungen an, wie zum Beispiel Prädikat Pushdown. Der Optimierer kann Filterprädikate in die Datenquelle verschieben, sodass die physische Ausführung irrelevante Daten überspringen kann. Bei Parquet-Dateien können ganze Blöcke übersprungen und Vergleiche auf Strings über die Dictionary-Codierung zu günstigeren Ganzzahl-Vergleichen gemacht werden. Im Fall von relationalen Datenbanken werden Prädikate in die externen Datenbanken geschoben, um den Datenverkehr zu reduzieren. Zweitens kompiliert Catalyst Operationen in physische Pläne für die Ausführung und generiert JVM-Bytecode für diese Pläne, der oft besser als handgeschriebener Code ist. Zum Beispiel kann es intelligent zwischen Broadcast-Joins und Shuffle-Joins wählen, um den Netzwerkverkehr zu reduzieren. Sie können auch Optimierungen auf niedrigerer Ebene durchführen, z. B. teure Objektzuordnungen vermeiden und virtuelle Funktionsaufrufe reduzieren. Daher erwarten wir bei der Migration zu DataFrames Leistungsverbesserungen für vorhandene Spark-Programme.
Hier ist der Leistungsbenchmark Ссылка
Tags und Links apache-spark spark-dataframe apache-spark-sql
{kind=link}