Ich lese das O'Reilly CouchDB Buch. Ich bin verwirrt über den reduce / re-reduce / incremental-MapReduce Teil auf Seite 64. Zu viel ist im O'Reilly Buch mit dem Satz
rhetorischWenn Sie daran interessiert sind, die Funktionalität der inkrementellen Verkleinerung von CouchDB zu erweitern, werfen Sie einen Blick auf Googles Paper zu Sawzall, ...
Wenn ich das Wort "inkrementell" richtig verstehe, bezieht es sich auf eine Art Additionsoperation in der B-Baum-Datenstruktur. Ich kann noch nicht sehen, warum es etwas Besonderes ist über typische Map-Reduce, wahrscheinlich noch nicht verstehen. In CouchDB erwähnt es, dass es keine Nebenwirkungen mit der Kartenfunktion gibt - gilt das auch für die Reduzierung?
Warum wird MapReduce in CouchDB "inkrementell" genannt?
Diese Seite, die Sie verlinkt haben, hat es erklärt.
Die Ansicht (die den gesamten Punkt der Kartenreduzierung in CouchDB darstellt) kann aktualisiert werden, indem nur die Dokumente indexiert werden, die seit der letzten Indexaktualisierung geändert wurden. Das ist der inkrementelle Teil.
Dies kann erreicht werden, indem die Reduce-Funktion referenziell transparent ist, was bedeutet, dass sie immer die gleiche Ausgabe für eine gegebene Eingabe zurückgibt.
Die Reduzierungsfunktion muss auch kommutativ und assoziativ für die Array-Werteingabe sein, was bedeutet, dass Sie dasselbe Ergebnis erhalten, wenn Sie den Reduzierer am Ausgang desselben Reduzierers ausführen. In dieser Wiki-Seite wird ausgedrückt:
%Vor%Rereduce ist, wo Sie die Ausgabe von mehreren Reduziereraufrufen nehmen und diese durch den Reduzierer erneut ausführen. Dies ist manchmal erforderlich, da CouchDB Daten über den Reduzierer in Stapeln sendet, sodass manchmal nicht alle Schlüssel, die reduziert werden müssen, einmal gesendet werden.
Um nur etwas hinzuzufügen, was Benutzer1087981 gesagt hat, ist die Reduce-Funktionalität inkrementell, da der Reduce-Prozess von CouchDB ausgeführt wird.
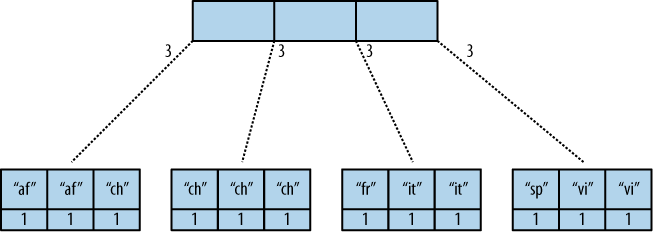
CouchDB verwendet den B-Tree, den er aus der View-Funktion erstellt, und führt im Wesentlichen die Reduzierungsberechnungen in Wertklumpen durch. Hier ist ein sehr einfaches Modell eines B-Baumes aus dem O'Reilly Guide , der die Blattknoten für Das Beispiel in der von Ihnen zitierten Sektion .
Reduziere B-Baum http://guide.couchdb.org/draft/views/02.png
Also, warum ist das inkrementell? Nun, die letzte Reduzierung wird nur zur Abfragezeit ausgeführt und alle reduzieren Berechnungen werden im B-Tree-Anzeigeindex gespeichert. Nehmen wir an, Sie fügen Ihrer DB einen neuen Wert hinzu, der ein weiterer Wert für "fr" ist. Die Berechnungen für den 1., 2. und 4. Knoten müssen nicht wiederholt werden. Der neue Wert "fr" wird hinzugefügt, und die Funktion reduce wird nur für diesen dritten Blattknoten neu berechnet.
Anschließend wird zur Abfragezeit die endgültige ( rereduce=true ) Berechnung für die indizierten Werte durchgeführt und der endgültige Wert zurückgegeben. Sie können sehen, dass diese inkrementelle Art der Reduzierung es ermöglicht, die für die Neuberechnung erforderliche Zeit nur für die neu hinzugefügten Werte und nicht für die Größe des vorhandenen Datensatzes zu berechnen.
Ohne Nebenwirkungen ist ein weiterer wichtiger Teil dieses Prozesses. Wenn Ihre reduce-Funktionen zum Beispiel darauf beruhen, dass ein anderer Status beibehalten wird, während Sie alle Werte durchlaufen, funktioniert das möglicherweise beim ersten Durchlauf, aber wenn ein neuer Wert hinzugefügt und eine inkrementelle Reduzierungsberechnung durchgeführt wird, würde dies nicht der Fall sein Habe diesen Zustand nicht zur Verfügung - und es würde nicht zum richtigen Ergebnis führen. Deshalb müssen reduce-Funktionen nebenwirkungsfrei sein oder wie user1087981 es "referenziell transparent" macht
Tags und Links mapreduce data-structures terminology couchdb
{kind=link}