Ich habe ein Array von Punkten im unbekannten dimensionalen Raum, wie zum Beispiel:
%Vor%und ich möchte den durchschnittlichen euklidischen Abstand zwischen allen Punkten finden.
Bitte beachten Sie, dass ich über 20.000 Punkte habe, also möchte ich das so effizient wie möglich machen.
Danke.
Nun, ich denke nicht, dass es einen superschnellen Weg gibt, dies zu tun, aber das sollte es tun:
%Vor%Um die Anzahl der Bewertungen herum geht es nicht:
Aber Sie können sich die Kosten all dieser Quadratwurzeln sparen, wenn Sie mit einem ungefähren Ergebnis zurechtkommen . Es hängt von Ihren Bedürfnissen ab.
Wenn Sie einen Durchschnitt berechnen, rate ich Ihnen, nicht alle Werte vor der Berechnung in ein Array zu setzen. Berechnen Sie einfach die Summe (und die Summe der Quadrate, wenn Sie auch die Standardabweichung benötigen) und werfen Sie jeden Wert bei der Berechnung weg.
Seit alt text http://www.equationsheet.com/latexrender/pictures/12a8776b729c0f86352787b4f0125226.gif und alt text http://www.equationsheet.com/latexrender/pictures/2c405dc40c555302bfb6183ec34af822.gif , Ich weiß nicht, ob das bedeutet, dass du irgendwo mit zwei multiplizieren musst.
Nachdem Sie nun Ihr Ziel festgelegt haben, die Ausreißer zu finden, sind Sie wahrscheinlich besser dran, den Stichprobenmittelwert und damit die Stichprobenvarianz zu berechnen, da beide Operationen Ihnen eine O (nd) -Operation geben. Damit sollten Sie in der Lage sein, Ausreißer zu finden (z. B. mit Ausnahme von Punkten, die weiter vom Mittelwert als ein Bruchteil des Std. Dev. Entfernt sind), und dieser Filterungsprozess könnte in O (nd) Zeit für insgesamt O ( nd).
Sie könnten an einer Auffrischung der Ungleichheit von Tschebyscheff interessiert sein.
Lohnt es sich jemals, ohne eine funktionierende Lösung zu optimieren? Auch die Berechnung einer Entfernungsmatrix über den gesamten Datensatz muss selten schnell sein, da Sie dies nur einmal tun müssen - wenn Sie einen Abstand zwischen zwei Punkten kennen müssen, schauen Sie einfach nach, er ist bereits berechnet.
Wenn du also keinen Platz zum Starten hast, hier ist einer. Wenn Sie dies in Numpy tun möchten, ohne intransparent oder C zu schreiben, sollte das kein Problem sein, obwohl Sie vielleicht diese kleine vektorbasierte virtuelle Maschine mit dem Namen " numexpr " (verfügbar auf PyPI, trivial bis intall), was in diesem Fall einen 5-fachen Leistungsschub gegenüber Numpy allein ergab.
Im Folgenden habe ich eine Abstandsmatrix für 10.000 Punkte im 2D-Raum berechnet (eine 10K x 10k-Matrix, die den Abstand zwischen allen 10k-Punkten angibt). Dies dauerte 59 Sekunden auf meinem MBP.
%Vor%Wenn Sie eine schnelle und ungenaue Lösung wünschen, könnten Sie wahrscheinlich den Fast Multipole Method -Algorithmus anpassen.
Punkte, die durch eine kleine Distanz voneinander getrennt sind, haben einen geringeren Beitrag zur endgültigen Durchschnittsdistanz, daher wäre es sinnvoll, Punkte in Cluster zu gruppieren und die Abstände der Cluster zu vergleichen.
Tags und Links python algorithm performance numpy distance
![Summe [ni, {i, 0, n}] = http://www.equationsheet.com/ lateatrender / Bilder / 27744c0bd81116aa31c138ab38a2aa87.gif](http://www.equationsheet.com/latexrender/pictures/27744c0bd81116aa31c138ab38a2aa87.gif){kind=link}
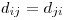{kind=link}
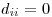{kind=link}